“วันนี้วันจันทร์”
นี่อาจจะเป็นวันที่หลายคนไม่อยากให้มาถึงเพราะเป็นสัญญาณว่าต้องกลับไปทำงานอีกครั้งหนึ่งแล้ว แต่สำหรับผม(และอีกหลายคน) วันนี้ถือเป็นไฮไลต์ของสัปดาห์เลยก็ว่าได้เพราะมันเป็นเช้าที่จะได้ตื่นมาพบกับ playlist ใหม่ Discover Weekly ของ Spotify ที่อัพเดทเพลงใหม่ๆ ให้เราได้ลองฟังกันทุกอาทิตย์ และยิ่งเวลาผ่านไปนานเท่าไหร่ Spotify ก็ยิ่งเลือกเพลงได้ตรงใจ(และตรงหู) เรามากขึ้น จนหลังๆ มานี่เรียกได้ว่าแทบจะกดหัวใจให้ทุกเพลงที่ถูกเลือกมาทุกอาทิตย์เลยก็ว่าได้ ทำให้เริ่มสงสัยว่าเจ้าแอพพลิเคชั่นตัวนี้รู้จักรสนิยมเราดีมากและน่าทึ่งจนพูดได้ว่า “มึงรู้ดีกว่าแฟนที่คบกันมายี่สิบสามสิบปีหรือบางทีดีกว่ากูด้วยซ้ำ!”
ตั้งแต่เปิดตัวในปี ค.ศ. 2015 ฟีเจอร์นี้ได้รับเสียงตอบรับที่ดีมาอย่างต่อเนื่องจนหลายคนถึงขั้นเขียนลงทวิตเตอร์ว่า
“ถึงตอนนี้ Discover Weekly ของ Spotify รู้จักฉันดีมากจนถ้าถูกมันขอแต่งงานฉันคงตอบ yes”
“มันดีจนน่ากลัวที่ Discover Weekly ของ Spotify รู้จักฉันเหมือนกับ‘คนรักเก่าที่เคยร่วมผ่านประสบการณ์เฉียดตายด้วยกัน’ เลยทีเดียว”
30 เพลงใหม่จะถูกเลือกมาทุกเช้าวันจันทร์จากฐานข้อมูลของเพลงกว่า 30 ล้านเพลง(ในปีค.ศ. 2018) หรือเทียบเป็นเปอร์เซ็นต์แล้วคือ 0.000001% ของเพลงทั้งหมดจะถูกเลือกมาทุกอาทิตย์ให้โดนใจเรา ซึ่งอาจเป็นอะไรที่น่าเหลือเชื่อ แต่เมื่อรู้แบบนี้ยิ่งทำให้สนใจมากขึ้นไปอีกว่ากระบวนการทั้งหมดต้องมีอะไรแสนฉลาดอยู่เบื้องหลัง เพราะมันไม่มีทางที่จะเป็นระบบสุ่ม (random) เลือกเพลงมาให้เราอย่างแน่นอน
และเมื่อคันก็ต้องเกา สงสัยอยากรู้ก็ต้องหาข้อมูล สุดท้ายหลังจากใช้เวลาค้นหาคำตอบอยู่นาน ก็พอจะเห็นภาพว่ากลไกหลังบ้านทำงานกันยังไง แต่ต้องบอกก่อนว่านี่เป็นข้อมูลที่เก็บมา ไม่มีทางที่จะถูกต้องทั้งหมด แต่เป็นแนวทางที่พอจะทำให้เข้าใจได้ว่าทำไม Spotify ถึงรู้ใจเรามากขนาดนี้
ก่อนอื่น ย้อนกลับไปดูบริการอื่นๆ ของ Online Music ในยุค2000s อย่าง Songza กันก่อนตอนนั้นเราเริ่มเห็นฟีเจอร์การทำ playlist ด้วยมือเป็นครั้งแรกๆ บนโลกออนไลน์ สิ่งที่เกิดขึ้นคือพวกเขาให้มนุษย์ปุถุชนคนทั่วไปที่อาจจะช่ำชองเรื่องเพลง ฟังเพลงมาเยอะมาก แล้วก็สร้าง playlist ต่างๆ ขึ้นมา เพลงที่มันฟังแล้วน่าจะอยู่ด้วยกันก็เอามาจับยัดๆ ใส่เข้าไป ให้ลองนึกถึง ‘เทปอัด’ หรือ mixed tape ในยุค90s ที่เรานำเทปเปล่ามาอัดเพลงให้กันนั้นแหละครับเพียงแต่อยู่ในรูปดิจิทัล(ตอนหลัง Beats ก็ทำเหมือนกัน)
มันพอถูไถไปได้แหละ เพียงแต่ว่ารสนิยมของ playlist แต่ละอันก็ขึ้นอยู่กับผู้สร้างคนนั้นๆ ซึ่งก็อาจจะทั้งตรงบ้างไม่ตรงบ้างกับรสนิยมของผู้ฟังแต่ละคน
ยุคต่อมาเราเห็น Pandora ก็เริ่มทำ playlist แบบนี้บ้างแต่ยกระดับขึ้นมาอีกหน่อยหนึ่งโดยการสร้าง tag ให้กับเพลงแต่ละเพลง และเขาก็ให้มนุษย์(อีกนั้นแหละ)มาฟังเพลงแล้วก็เขียน tag สั้นๆ สำหรับการจัดหมวดหมู่ของเพลง(sad, happy, upbeat, pop, musical ฯลฯ) ต่อมาโปรแกรมเมอร์ก็เขียนโค้ดให้รวมกลุ่มเพลงที่มี tag คล้ายๆ กันเพื่อสร้าง playlist ต่างๆ ขึ้นมา ผู้ใช้งานก็มีความสุขมากขึ้นอีกนิดหน่อย
ต่อมาไม่นานที่ MIT Media Lab ก็มีแพลตฟอร์มหนึ่งชื่อ The Echo Nest ที่ใช้เทคโนโลยีที่แตกต่างออกไปในการคัดแยกเพลงแต่ละเพลงออกจากกัน พวกเขานำอัลกอริทึม (algorithm) คอมพิวเตอร์มาใช้เพื่อวิเคราะห์เพลง ทั้งข้อมูลเสียงและเนื้อหา (textual content) ต่างๆ เพื่อจะแบ่งเพลงออกจากกัน ซึ่งสามารถแนะนำเพลงตามความชอบและสร้าง playlist ได้ด้วย
อีกด้านหนึ่ง Last.fm (อันนี้เคยใช้อยู่พักหนึ่งก่อนหันไป Spotify) ที่ยังให้บริการอยู่ในวันนี้ พวกเขาใช้กระบวนการที่เรียกว่า ‘collaborative filtering เพื่อบ่งบอกว่าเพลงไหนผู้ฟังน่าจะชอบจากพฤติกรรมการฟังของคุณและคนอื่นๆ ที่อยู่ในระบบ
แล้วหลังบ้านของ Spotify เป็นยังไง? ทำไมถึงเลือกเพลงที่โดนใจผู้ฟังและเข้าใจรสนิยมของผู้ฟังได้แม่นยำมากกว่าผู้ให้บริการอื่นๆ ?
คำตอบคือการรวมของดีมาไว้ด้วยกันครับ พวกเขาไม่ได้ใช้โมเดลเดียวในการสร้าง recommendation ให้กับผู้ฟัง แต่เป็นการผสมผสานกลยุทธ์ต่างๆ ที่ถูกใช้โดยผู้ให้บริการเจ้าอื่น แล้วสร้างเป็นอาวุธลับอันทรงพลังของตัวเอง โดยการสร้าง Discover Weekly นั้น Spotify ใช้สามโมเดลด้วยกันก็คือ
- Collaborative Filtering (คล้ายกับ Last.fm) Model ที่วิเคราะห์พฤติกรรมของผู้ใช้งานและคนอื่นๆ
- Natural Language Processing (NLP) Model ที่วิเคราะห์ข้อมูลเนื้อหา
- Raw Audio Model ที่วิเคราะห์ไฟล์เพลงแบบดิบๆ
ลองมาดูกันว่าแต่ละโมเดลทำงานกันยังไง
1. Collaborative Filtering Model – ซึ่งหลายๆ คน พอได้ยินคำนี้ก็มักจะนึกถึง Netflix เพราะพวกเขาเป็นหนึ่งในบริษัทแรกๆ ที่เริ่มใช้โมเดลนี้ เพราะสร้าง recommendation โดยการนำเรตติ้งแบบให้ดาวของผู้ใช้งานคนหนึ่ง มาเป็คำแนะนำบอกต่อให้กับลูกค้าคนอื่นๆ โดยหลังจากที่ Netflix ประสบความสำเร็จ Collaborative Filtering Model ก็เริ่มถูกใช้กันอย่างกว้างขวางและกลายเป็นจุดเริ่มต้นของระบบ recommendation ของที่อื่นๆ ด้วย
แต่ถ้าใครใช้ Spotify จะรู้ว่าพวกเขาไม่มีระบบดาว(มีแต่หัวใจ/ไม่หัวใจ)แต่ที่น่าสนใจก็คือว่าข้อมูลของ Spotify นั้นได้รับมาจากฟีดแบคการฟังเพลงเช่น เราฟังเพลงนี้วนไปกี่รอบ เราเซฟเพลงนั้นใส่ใน playlist ของตัวเองรึเปล่า หรือแม้แต่การที่เรากดเข้าไปดูหน้าข้อมูลศิลปินคนนั้นหลังจากที่ฟังเพลงก็ถูกบันทึกไว้ด้ว
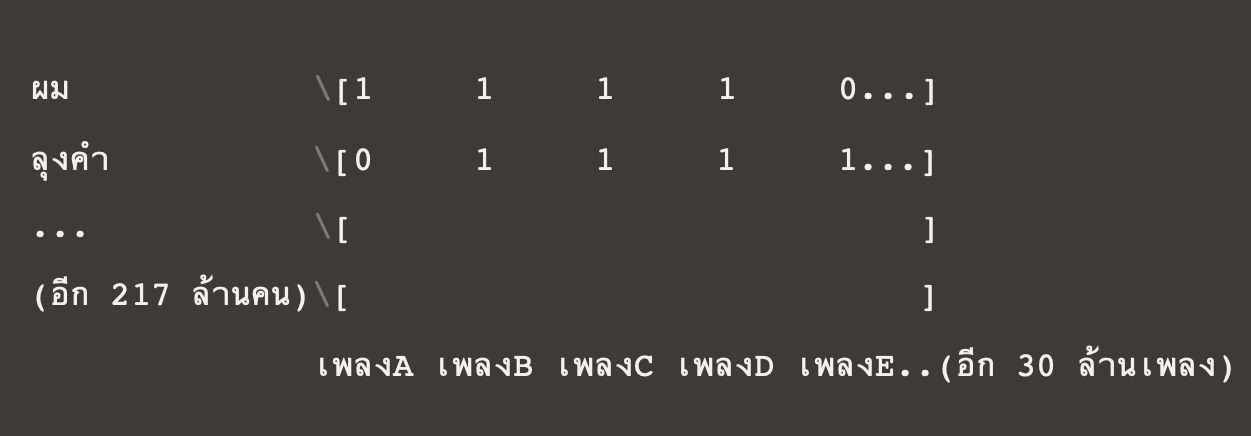
Collaborative Filtering Model ทำงานแบบนี้ครับ สมมุติว่าผมชอบเพลง A, B, C, D และผู้ใช้งานอีกคนหนึ่งสมมติว่าชื่อลุงคำ ชอบเพลง B, C, D, E ระบบก็จะแนะนำลุงคำว่าให้ลองฟังเพลง A ดูนะเพราะน่าจะชอบ (มีเพลงB, C, D ที่ชอบเหมือนกัน) และกลับมาบอกผมว่าลองฟังเพลง E ดูสิ เพราะคนที่รสนิยมคล้ายๆ กันชอบสิ่งที่ Spotify ทำก็คือว่าใช้เมทริกซ์ (matrix) ที่เป็นตารางสี่เหลี่ยมบรรจุตัวเลข 0,1 เอาไว้เต็มไปหมดโดยแต่ละแถวของเมทริกซ์คือผู้ฟังแต่ละคน ส่วนคอลัมน์ก็คือเพลงแต่ละเพลง หน้าตาก็จะได้ประมาณนี้
ผม [1 1 1 1 0…]
ลุงคำ [0 1 1 1 1…]
… [ ]
(อีก217 ล้านคน) [ ]
เพลง A เพลง B เพลง C เพลง D เพลง E..(อีก30 ล้านเพลง)
แล้วหลังจากนั้นก็เอาไปเข้าสูตรทางคณิตศาสตร์(ซึ่งจะอธิบายก็คงต้องยาวอีกเป็นหลายหน้ากระดาษ แค่เข้าใจว่ามันเป็นสูตรปรุงอาหารของ Spotify ละกันครับ) ออกมาเป็นเวกเตอร์ x และ y โดยที่ x คือรสนิยมของผู้ใช้งานคนหนึ่ง และ y คือโปรไฟล์ของเพลงแต่ละเพลง
ซึ่งเจ้าเวคเตอร์ x,y เพียงอันเดียวมันก็เป็นแค่ตัวเลขที่ไร้ประโยชน์ แต่ว่าถ้าลองเอาหลายๆ อันมาเทียบกันแล้วมันคือข้อมูลที่มีค่ามหาศาลเลยทีเดียว ถ้าอยากรู้ว่ารสนิยมการฟังเพลงของใครคล้ายกันบ้าง ก็เอาเวกเตอร์ x ของเราไปเทียบกับเวกเตอร์ของทุกคน หลังจากนั้นก็ได้ผลลัพธ์ออกมาเป็นผู้ใช้งานต่างๆ ที่คล้ายกับเรา เหมือนกันกับเวคเตอร์ y ที่เอามาเทียบกันว่าเพลงไหนที่มีโปรไฟล์คล้ายคลึงกันก็ดึงข้อมูลออกมา
Collaborative Filtering Model ทำงานได้ดีในระดับหนึ่งแต่ Spotify ยังไม่หยุดแค่นั้น มาต่อโมเดลที่สองกันเลย
2. Natural Language Processing (NLP) Model – ข้อมูลดิบของโมเดลชนิดนี้ก็คือคอนเทนต์และข้อมูลต่างๆ ที่เกี่ยวข้องกับเพลงนั้นๆ ยกตัวอย่างเช่น metadata, ข่าวที่เกี่ยวข้อง, บล็อกโพสต์ และข้อมูลที่เป็นภาษาเขียนคำพูดต่างๆ บนอินเตอร์เน็ต Natural Language Processing คือเทคโนโลยีรูปแบบหนึ่งที่ถูกสร้างขึ้นมาเพื่อให้คอมพิวเตอร์นั้นเข้าใจภาษาของมนุษย์เวลาสื่อสารกันซึ่งมันเป็นสาขาของเทคโนโลยีที่กว้างมากด้วยตัวมันเอง
เอาเป็นว่าสิ่งที่ Spotify ทำก็คือสร้างบอทขึ้นมาเพื่อให้วิ่งไล่ดึงข้อมูลที่อยู่บนเว็บไซต์ต่างๆ บนอินเตอร์เน็ตตลอดเวลา โดยหาโพสต์ที่เขียนเกี่ยวกับเพลงนั้นๆ หาข้อมูลว่ามีคนพูดถึงแต่ละเพลงยังไง พูดถึงศิลปินคนนั้นยังไง คำสรรพนามที่ใช้เพื่ออธิบายเพลงและภาษา(จีน, ไทย, อังกฤษฯลฯ) ไหนที่ถูกใช้บ่อยเมื่อเขียนถึงเพลงเหล่านี้ มีศิลปินคนไหนที่หรือเพลงไหนที่ถูกพูดถึงในโพสต์ด้วยไหม
หลังจากนั้นพวกเขาก็นำ ‘top terms’ หรือคำที่คนมักใช้เวลาพูดถึงเพลงเหล่านี้ ซึ่งอาจจะเป็นหลายร้อยหลายพันคำที่เปลี่ยนทุกวันแต่ละคำก็จะมีน้ำหนักความสำคัญที่ไม่เท่ากัน (คิดโดยใช้สูตรของตัวเอง) แล้วหลังจากนั้นก็สร้างเวกเตอร์ของเพลงขึ้นมาเหมือนกับ Collaborative Filtering Model ซึ่งสามารถนำมาเทียบกันได้ว่าเพลงไหนที่มีความคล้ายคลึงกันบ้าง
3. Raw Audio Model – เป็นการวิเคราะห์ไฟล์แบบดิบๆ ซึ่งโมเดลที่สามนี้แหละที่จะช่วยเพิ่มความแม่นยำในบริการเลือกเพลงให้ตรงใจลูกค้า ความสำคัญของโมเดลนี้อีกอย่างหนึ่งที่ไม่เหมือนกับอีกสองโมเดลก็คือมันสามารถวิเคราะห์เพลงใหม่ๆ ที่เข้ามาในฐานข้อมูลได้อีกด้วย
ซึ่งอันนี้คือจุดแข็งอย่างหนึ่งเลยทีเดียว เพราะเพลงใหม่ๆ เมื่อเข้าสู่ฐานข้อมูล ถ้าไม่มีโมเดลนี้ เพลงที่ไม่ได้มาจากศิลปินชื่อดังที่ได้รับการโปรโมทอาจจะถูกกลืนหายไปกับระบบเลย เพราะถ้ามีแค่สองโมเดลด้านบน Collaborative Filtering ก็ไม่รู้จะไปเทียบกับใคร NLP ก็หาข้อมูลบนอินเตอร์เน็ตไม่เจอ เพราะฉะนั้นโมเดลการวิเคราะห์ไฟล์เพลงแบบดิบๆ แบบนี้แหละที่จะทำให้เพลงใหม่ๆ นั้นมีโอกาสได้ลืมหูลืมตา
Discover Weekly ของผมมีเพลงใหม่ๆ ที่เพิ่งเปิดตัวจากศิลปิน
ที่ไม่เคยได้ยินชื่อเข้ามาอยู่บ่อยครั้งก็ด้วยสาเหตุนี้
เทคโนโลยีที่อยู่เบื้องหลังการวิเคราะห์ข้อมูลดิบคือ ‘convolutional neural networks’ ที่เป็นเทคโนโลยีเดียวกันกับพวกซอฟต์แวร์ตรวจสอบใบหน้า (facial recognition) ในกรณีของSpotify เจ้าเทคโนโลยีตัวนี้จะใช้ข้อมูลเสียงแทนที่จะใช้ข้อมูลพิกเซล (ใครที่สนใจแนะนำให้ลองอ่านบทความนี้ดูครับสนุกมาก : Audio and Image Features used for CNN)
หลังจากผ่านกระบวนการทั้งหมดแล้ว เพลงแต่ละเพลงก็จะมีคาแรกเตอร์เป็นของตนเองติดเอาไว้ เป็นเหมือนลายเซ็นว่าคีย์เพลงสูงต่ำ โหมดความเร็วความดังคือแบบไหน แล้วหลังจากนั้นเมื่อมีคาแรกเตอร์แล้วก็ทำให้ Spotify เลือกได้ว่าเพลงนี้มีความใกล้เคียงกับเพลงไหน และผู้ฟังคนไหนน่าจะชอบฟังเพลงนี้บ้าง
และนั่นก็คือวิธีที่ทาง Spotify สร้าง Discover Weekly playlist ให้กับผมทุกเช้าวันจันทร์ ซึ่งจะว่าไปแล้ว กว่าจะได้มาก็ไม่ใช่งานง่ายๆ เลยทีเดียวโมเดลเหล่านี้ก็เป็นเพียงส่วนหนึ่งของระบบทั้งหมดของ Spotify ซึ่งมันซับซ้อนกว่านี้มาก แต่ก็ทำให้เราเห็นว่าบริษัทที่ประสบความสำเร็จนั้นใส่ใจในทุกรายละเอียดและผู้ใช้บริการจนสัมผัสได้
อีกอย่างหนึ่งที่อยากฝากให้สังเกตก็คือว่า ข้อมูลมากมายที่ถูกนำมาใช้นั้นส่วนมากแล้วล้วนมาจากผู้ใช้งาน(นอกจากการวิเคราะห์ไฟล์เพลง) สิ่งที่น่าสนใจก็คือว่า นี่เป็นโมเดลการเติบโตของธุรกิจเทคโนโลยีในปัจจุบัน ซึ่งล้วนมีเรื่องข้อมูลมาเกี่ยวข้องทั้งสิ้น
การเก็บข้อมูลลักษณะแบบนี้ถือว่าเป็นการเอื้อประโยชน์ต่อกันสร้างประสบการณ์ใช้งานให้ดีขึ้น(ซึ่งก็คล้ายกับ Netflix) แม้จะมีบ้างที่ถูกนำไปสร้างเป็นโฆษณาเพื่อดึงดูดลูกค้าใหม่ๆ บ้าง(อ่านเพิ่มเติม : Spotify Unearths More Weird, Wonderful Data About Your Playlists and Listening Habits แต่ก็ถือว่าไม่ได้ใช้ไปในทางเสียหายหรือคนที่เห็นจะรู้สึกแย่กับผลิตภัณฑ์หรือแบรนด์แต่อย่างใด
ตราบใดที่ Spotify ยังอยู่ ผมก็ยังดีใจที่มีวันจันทร์
อ้างอิงข้อมูลจาก