เราอยู่ในยุคของข้อมูล, คนทำงานกับข้อมูลคืออาชีพที่เซ็กซี่ที่สุดในศตวรรษ, ข้อมูลเดี๋ยวนี้มีค่ากว่าน้ำมันอีก!
เราได้ยินประโยคแนวๆ นี้ รวมถึงคำที่ใช้กันบ่อยๆ อย่าง Big Data, Open Data หรือ Data Science มาสักพักละ ใช่แล้วล่ะ เรากำลังอยู่ในยุคที่ (พยายาม) ใช้ข้อมูลกันมากขึ้นจริงๆ
ข้อมูลจำนวนมหาศาลในโลกนี้ หากนำมาผ่านการวิเคราะห์และตีความ มันเอามาใช้ประโยชน์ได้จริงๆ นะ (ลองอ่านการใช้ประโยชน์จากข้อมูลในแง่มุมต่างๆ ได้จากซีรีส์ Data for Future ที่ The MATTER เคยทำไว้ https://thematter.co/tag/data-for-future) แถมอาชีพที่ทำงานเกี่ยวกับข้อมูลก็เป็นที่ต้องการและเติบโตทางด้านรายได้มากขึ้นเรื่อยๆ
The MATTER เคยคุยกับ Data Café โครงการที่เปิดประตูให้กับคนที่อาจจะไม่ได้เรียนจบหรือมีประสบการณ์ในสายอาชีพนี้ แต่พอมีพื้นฐานและที่สำคัญคือมีความสนใจได้เข้าไปเรียนรู้และฝึกฝน ซึ่ง Data Café ได้จัดโครงการ Fellowship Program ครั้งแรกขึ้นเมื่อปลายปีที่แล้ว และให้ผู้ผ่านการคัดเลือกเข้าไปอบรมเป็นเวลา 3 เดือน
และนี่คือ 6 ผลงานที่ผ่านเข้ารอบสุดท้าย ที่ทำให้เราเห็นว่าข้อมูลสามารถหยิบจับเอามาทำอะไรสนุกๆ ได้หลายอย่างแตกต่างกันไป
หวยไหนใบ้แม่นเฟร่อ
สมมติเราซื้อลอตเตอรี่มา 1 ใบ โอกาสถูกรางวัลเลขท้ายสองตัวจะอยู่ที่ 1% แต่ช้าก่อน! ถ้าข่าวจากบางสำนัก อาจเพิ่มโอกาสของเราเป็น 1.24% ได้

ช้าก่อน! (อีกรอบ) นี่ไม่ใช่คำชวนเชื่อหรือชี้นำอะไร แต่เป็นผลการวิเคราะห์จากงานที่ ‘เทพกร ธนูถนัด’ ได้พัฒนาขึ้นในโครงการของ Data Café เขาได้ทำการสำรวจตรวจหาข้อมูลจากเว็บไซต์ของสำนักข่าว 4 แห่งคือ thairath.co.th, khaosod.co.th, matichon.co.th และ manager.co.th ในช่วงเวลาหนึ่งปี (ระหว่างวันที่ 31 กันยายน 2016 ถึง 31 กันยายน 2017) ด้วยความสงสัยแบบสนุกๆ ว่าข่าวที่นำเสนอเรื่องเลขเด็ดของสำนักข่าวไหนมีความ ‘แม่น’ มากที่สุด รวมไปถึงว่าจังหวัดและสิ่งศักดิ์สิทธิ์ไหนที่เกี่ยวข้องกับเลขเด็ดมากที่สุดด้วย
“ผมก็เริ่มจากความสนใจทั่วไปของคนไทยอย่างเรื่องสิ่งศักดิ์สิทธิ์ครับ แล้วพอไปดูข้อมูลปรากฏว่ามันมีข้อมูลที่เชื่อมโยงกับหวยเยอะมากๆ เราก็ตั้งคำถามเล่นๆ กับตัวเองว่า เอ เจ้าไหนใบ้แม่นสุดนะ จากนั้นก็ดึงข้อมูลมาวิเคราะห์ แล้วก็จะเริ่มสังเกตเห็นข้อมูลที่น่าสนใจ อย่างเช่น ช่วงเปิดเทอมเนี่ย ข่าวจากเลขเด็ดจะเยอะกว่าช่วงอื่นๆ นะ (อาจจะเป็นช่วงมีค่าใช้จ่ายเนอะ) หรือแหล่งเลขเด็ดในข่าวนี่ส่วนใหญ่จะเป็น ‘ตะเคียน’ (204 ข่าว) รองลงมาก็ ‘ฝัน’ (190 ข่าว)”
เทพกรบอกว่าเขาเป็นนักพัฒนาซอฟต์แวร์ เคยแต่ทำงานกับชุดตัวเลขที่พร้อมใช้งานแล้ว แต่ไม่เคยทำงานกับข้อมูลที่เป็นข้อความมาก่อน ดังนั้นความท้าทายจึงอยู่ที่การเลือกใช้ข้อมูลที่เป็นประโยชน์จากข้อมูลที่มีจำนวนมาก ส่วนผลงานที่ใช้การเชื่อมโยงข้อมูลจากข่าวกับสถานการณ์จริง เทพกรมองว่าน่าจะเอาไปใช้ในบริบทอื่นๆ ได้ อย่างเช่น (สมมตินะ) ดูว่านายกฯ เดินทางไปจังหวัดไหน แล้วเกิดการเปลี่ยนแปลงยังไงบ้าง
ลองเข้าไปดูผลงาน ‘หวยไหนใบ้แม่นเฟร่อ’ ได้ที่ https://storage.googleapis.com/lottery-dataviz/index.html สนุกดี!
ฝากเตือน : การพนันเป็นสิ่งผิดกฎหมาย และข้อมูลจากงานชิ้นนี้ไม่ได้จัดทำขึ้นเพื่อเป็นการชี้นำใดๆ ทั้งนั้นนะจ๊ะ
Movie Analysis
ปีที่แล้ว.. จำได้ไหมว่าหนังเรื่องไหนสนุกที่สุด?

‘ศิวพล เตชรัศมี’ ผู้เข้าร่วมโครงการที่สนใจเรื่องภาพยนตร์และชอบอ่านรีวิวหนังในเพจต่างๆ ก็เลยปิ๊งไอเดียขึ้นมาว่า เออ น่าจะลองรวมความคิดเห็นของทั้งผู้ชมและนักวิจารณ์มาวิเคราะห์ดูนะว่า พวกเขาพูดถึงหนังในปีที่ผ่านมาว่ายังไงบ้าง เขาเลยดึงเอาข้อมูลจากโพสต์และคอมเมนต์ในพันทิปและเฟซบุ๊กเกี่ยวกับภาพยนตร์ทั้งหมด 189 เรื่อง ที่เข้าฉายในโรงภาพยนตร์ช่วงมกราคม-สิงหาคม 2017 มาวิเคราะห์ว่าภาพยนตร์ถูกพูดถึงในแง่บวกหรือลบยังไงบ้าง
ปรากฏว่าเรื่องที่คนพูดถึงมากที่สุดในชุดข้อมูลที่ศิวพลรวบรวมมาคือเรื่อง ‘Dunkirk’ (11,598 โพสต์) รองลงมาคือ ‘Spider-Man Homecoming’ (11,556 โพสต์) และอันดับสามคือหนังไทยอย่าง ‘ฉลาดเกมส์โกง’ (9,204 โพสต์) ศิวพลยังใช้ Machine Learning เพื่อวิเคราะห์ sentiment ของชุดข้อมูลด้วย ด้วยความสงสัยว่าความเห็นบนโซเชียลมีเดียจะมีผลต่อรายได้ของภาพยนตร์ไหม
“ผลที่ออกมายังสรุปได้ไม่ชัดเจนเท่าไหร่ครับ เพราะจริงๆ มีปัจจัยอีกเยอะที่ต้องเอามาใส่ในการวิเคราะห์ แต่ก็เป็นจุดเริ่มต้นที่เอาไปพัฒนาได้ นี่ก็เป็นบทเรียนนึงครับว่า เวลาเราทำงานกับข้อมูลเยอะๆ เราตั้งคำถามที่เราต้องการหาคำตอบ แล้วหาวิธีวิเคราะห์ไปจัดการข้อมูล แต่ก็ต้องไม่ลืมตรวจสอบวิธีคิดหรือวิเคราะห์ของเราด้วยครับว่ามันถูกต้องหรือเปล่า”
ถึงอย่างนั้น ศิวพลก็มองว่าวิธีวิเคราะห์ sentiment ของหนังก็น่าจะสามารถนำไปปรับใช้กับแบรนด์ต่างๆ ได้ โดยดูฟีดแบคของลูกค้าบนโซเชียลฯ แล้วไปเปรียบเทียบกับยอดขาย เพื่อพัฒนาหรือปรับปรุงข้อผิดพลาดด้านต่างๆ
“ผมเองก็เป็นคนนึงที่เริ่มจากศูนย์ ไม่มีความรู้เรื่องโปรแกรมมิ่งเลยครับ แต่ตอนนี้ในโลกออนไลน์ มันมีคนสอนเราทุกอย่างเลย เราก็แค่เรียนรู้แล้วเอามาปรับในมุมที่เราต้องการจะใช้ อาจจะเริ่มจากเรื่องที่เราชอบหรือสนใจก่อน เพราะถ้าเป็นเรื่องที่เราสนใจ พอเรากระโดดลงไปในบ่อของข้อมูล แล้วเจออะไรที่ว้าว! เราก็จะตื่นเต้น”
ลองเข้าไปดูผลการวิเคราะห์จาก Movie Analysis ได้ที่ https://medium.com/@siwapoltecharatsami/data-cafe-fellowship-program-2a14d0a5b09e
แสนรู้
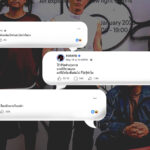
ยืมล็อกอินเพื่อนมาตั้งนะฮะ สงสัยหนักมาก ว่าทำไมผู้หญิงสมัยนี้ไม่ชอบผู้ชายกลางๆ กันล่ะฮะ
มาแนวยืมล็อกอินเพื่อนนี่ต้องกระทู้พันทิปแน่ๆ แล้ววันๆ นึงนี่ผุดขึ้นมากันหลายหมื่นกระทู้เลย ‘ชัยภูมิ ศิริพันธ์พรชนะ’ เล็งเห็นแหล่งข้อมูลมหาศาลนี้ แล้วเกิดนึกสนุกขึ้นมาว่า ถ้ามีวิธีที่แตกต่างออกไปจากการตั้งกระทู้ถามหรือเสิร์ชหาสิ่งที่เราสงสัยจากในมหาสมุทรข้อมูลนี้ล่ะ มันจะเป็นไปได้ไหม
“ผมนึกถึงแชทบอทสำหรับตอบคำถามครับ ตอนนี้แชทบอทส่วนใหญ่เป็นการตอบคำถามเฉพาะทาง เช่นบริการธนาคารหรือตอบปัญหาสุขภาพครับ ก็เลยสงสัยว่าถ้าเป็นข้อสงสัยทั่วๆ ไปในชีวิตเรา มีแชทบอทมาคอยช่วยตอบเนี่ย จะทำได้ไหม ก็เลยนึกถึงพันทิป ที่เป็นการตั้งกระทู้ถาม-ตอบอยู่แล้ว แต่เป็นเรื่องปัญหาชีวิต ปัญหาความรัก ไม่ได้มีคำตอบที่เป็นหลักการตายตัว ผมเลยลองเอามาสอนบอทดู”
ชัยภูมิรวบรวมข้อมูลจาก 254,166 กระทู้ (คำถาม) 1,617,894 คอมเมนต์ (คำตอบ) ซึ่งตั้งและตอบโดยผู้ใช้ 209,505 คนในพันทิป ในระยะเวลา 3 เดือน มาสอนบอทที่เขาตั้งชื่อว่า ‘แสนรู้’ โดยวิธี deep learning ทำให้เรียนรู้ข้อมูลได้จำนวนมากและหลากหลาย รวมถึงทำให้ระบบตอบคำถามได้โดยอ้างอิงจากบริบทของชุดข้อมูลที่นำมาสอน แม้คำถามนี้จะไม่เคยถูกถามมาก่อน
โดยข้อสังเกตที่น่าสนใจที่ชัยภูมิได้จากข้อมูลชุดนี้คือกระทู้ส่วนใหญ่ในพันทิป เป็นคำถามเกี่ยวกับความรัก ส่วนกระทู้ที่มีคนไปคอมเมนต์ตอบมากที่สุด ส่วนใหญ่จะเกี่ยวข้องกับการเมือง
“แต่ว่าแสนรู้จะไม่ได้มีคำตอบแบบหนึ่งต่อหนึ่งสำหรับคำถามนะครับ สมมติว่าสามคนถามคำถามในลักษณะเดียวกัน ก็อาจจะมีหลายคำตอบได้ เพราะเป็นความเห็นมากกว่าข้อเท็จจริงครับ แล้วข้อดีของการดึงข้อมูลจากพันทิป ก็คือภาษาที่ใช้ในเว็บเป็นภาษาที่คนใช้คุยกันอยู่แล้ว ทำให้บอทดูไม่เป็นหุ่นยนต์มากเกินไป แต่มันก็ทำให้ขั้นตอนการทำความสะอาดข้อมูลยากมากครับ เพราะภาษาไทยจะมีเรื่องของบริบทบ้าง การตัดคำบ้าง พิมพ์ผิดบ้าง เราก็ต้องทำงานหนักตรงนี้ เพราะเราไม่สามารถเอาข้อมูลผิดๆ มาสอนบอทได้”
ถึงอย่างนั้น ด้วยระยะเวลาที่จำกัด แสนรู้เลยยังได้รับการพัฒนาอยู่ในขั้นเดโมเท่านั้น แต่ถ้ามีจริงก็น่าลองใช้เหมือนกันนะ!
Feed Ranking
โหย แมกซ์ เจนกำลังจะออกเพลงใหม่แล้ว นั่น! พี่บุก็จะไปคอนนี้ด้วย ว้ายๆ พี่ตู่จะโพสต์รูปน่ารักจุงงง เนี่ย ไถฟีดไปเจอแต่อะไรที่ชอบก็ดียังงี้แหละ ชุบชูใจ
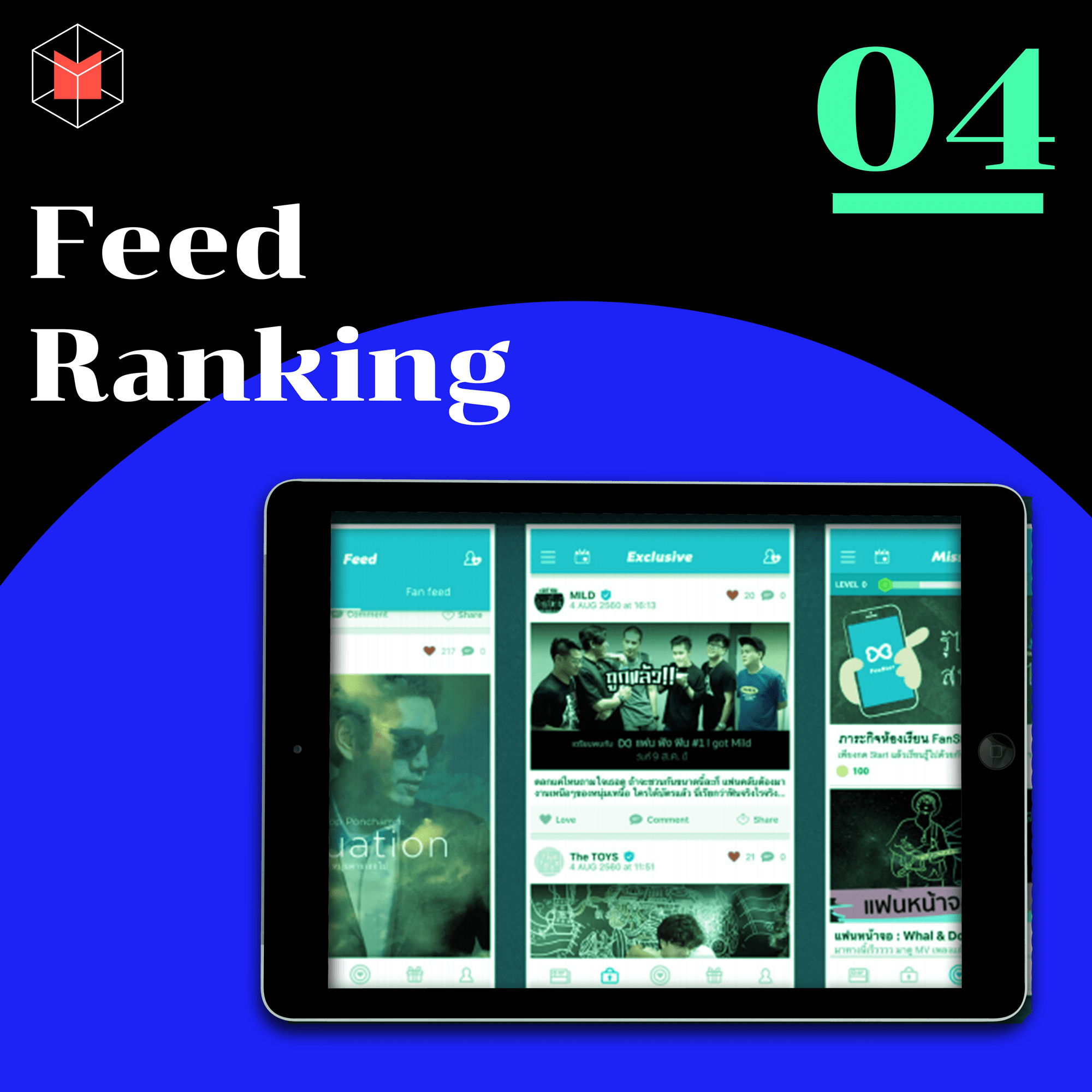
นี่คือสิ่งที่เกิดขึ้นจากผลงานของ ‘ประพีร์พัฒน์ เอื้อวิจิตรพจนา’ ที่เอาอัลกอริธึม Edgerank ของเฟซบุ๊ก (ที่จะเลือกเนื้อหาตามความสนใจของแต่ละคนมาขึ้นฟีด) มาปรับใช้กับแอปพลิเคชั่นอย่าง Fanster เป็นแอพฯ ที่ค่ายเพลง LoveIs ร่วมกับ MFEC รวบรวมเอาข้อมูลทุกอย่างเกี่ยวกับศิลปิน ไม่ว่าจะเป็นผลงาน ข่าวสาร เพลง หรือรูปภาพมาไว้ให้แฟนๆ ติดตาม โดยวิธีการจัดเรียงฟีดให้เหมาะกับพฤติกรรมผู้ใช้พิจารณจาก 3 องค์ประกอบคือ 1) ปฎิสัมพันธ์ของผู้ใช้กับโพสต์ของศิลปิน 2) ความน่าสนใจของฟีดศิลปิน และ 3) ความอัพเดทของเพจศิลปิน
“ผมไม่เคยจับต้องข้อมูลขนาดมหาศาลขนาดนี้มาก่อน พอได้เข้าไปอยู่ในพฤติกรรมและความสนใจของคนจำนวนมาก มันก็ทำให้เราได้เห็นกระแสอะไรที่น่าตื่นเต้นเหมือนกัน อีกความท้าทายสำหรับผมก็คือบางครั้งข้อมูลจำนวนมากมันก็ตอบโจทย์เราไม่ได้ เราอยากได้ในสิ่งที่มันไม่มี หรือในอีกรูปแบบหนึ่ง นั่นก็สอนให้เราหาวิธีจัดการหรือคิดแก้ปัญหาเฉพาะหน้าครับ”
ประพีร์พัฒน์บอกว่า จริงๆ อัลกอริธึม Edgerank นี่ก็เอาไปปรับใช้กับเว็บหรือแอพฯ อื่นๆ ได้ อย่างเว็บหางานหรือสั่งอาหารก็ได้ เพียงแต่ต้องปรับแต่งเพิ่มเติม เพราะอย่างที่เขาลองทำกับแอพฯ Fanster ผู้ใช้งาน 32-44% ก็ชอบการเรียงลำดับของฟีดที่สร้างขึ้นมาใหม่มากกว่าการเรียงลำดับแบบเดิม ซึ่งก็น่าจะเป็นผลดีกับธุรกิจมากขึ้น
“ในโลกของซอฟต์แวร์นะครับ ส่วนมากเราจะเจอแต่ประตูที่มีระบบล็อกอัตโนมัติ แล้วเราต้องทำตามระบบเพื่อปลดล็อกนั้นออกมา แต่เดี๋ยวนี้มันเริ่มมีหนึ่งอัลกอริธึมที่ทำงานกับผู้ใช้จำนวนมาก ทำให้อัลกอริธึมต้องมีความยืดหยุ่นเพื่อตอบสนองผู้ใช้แต่ละคน เราไม่ได้เป็นคนปรับจูน แต่อัลกอริธึมนี่แหละที่ต้องปรับให้เรา แล้วศาสตร์ด้าน Big Data และ Data Science นี่แหละครับ ที่มันเข้ามาช่วยให้พัฒนาอัลกอริธึมเหล่านี้ได้”
ตอนนี้ Feed Ranking กำลังอยู่ในขั้นตอนพิจารณาเพื่อนำไปใช้จริง ลองเข้าไปดูแอพฯ ก่อนได้ที่ https://fansterapp.com
PageLink

“ผมเคยทำแฟนเพจมาก่อน แล้วตอนนั้นรู้สึกว่าอยากหาคนที่สนใจเรื่องเดียวกันมาทำกิจกรรมร่วมกัน อยากมีปฏิสัมพันธ์ระหว่างเพจ แต่แทนที่เราจะไปนั่งดูทีละเพจในหมวดเดียวกัน ว่าเขาโพสต์อะไร เขาคุยอะไรกัน มันน่าจะมีระบบอะไรที่ช่วยเราคิดเรื่องนี้นะ”
นี่เป็นไอเดียเริ่มต้นของ ‘นวีน ปิติพรวิวัฒน์’ ที่สร้าง PageLink ระบบที่วิเคราะห์ปฏิสัมพันธ์ของผู้ใช้กับแฟนเพจต่างๆ บนเฟซบุ๊ก 254 เพจขึ้นมา เพื่อดูว่าผู้ใช้ที่กดไลก์หรือคอมเมนต์ในเพจนี้ ส่วนใหญ่มีแนวโน้มที่จะไปติดตามหรือคอมเมนต์เพจอื่นๆ เพจไหนอีกบ้าง
“ผมใช้ข้อมูลจากทาง MFEC ที่รวมเอาข้อมูลจากผู้ใช้ 47 ล้านคน ประมาณ 3 แสนโพสต์ แล้วเอาแบ่งเป็น 3 หมวด คือแบรนด์ รายการทีวีหรือเพจเฟซบุ๊ก และศิลปินกับ influencer โดยที่เวลาวิเคราะห์ ก็วิเคราะห์ทั้งในหมวดและระหว่างหมวด เช่นคนที่ติดตามแฟนเพจวงบอดี้แสลม ก็จะมีปฏิสัมพันธ์กับแฟนเพจของวงโปเตโต้หรือ Big Ass เยอะ หรือถ้าระหว่างหมวดก็เช่นว่า คนที่ติดตามเพจวี วิโอเลต ช่วงที่น้องไปเล่นหนังสั้นให้เซนทรัล คนก็จะมีปฏิสัมพันธ์กับเพจเซนทรัลเยอะขึ้น หรือช่วงที่สิงห์โปรโมตน้อง คนก็จะไปที่เพจนั้นมากขึ้นด้วย จริงๆ แบรนด์ก็ใช้ประเมินได้ว่าการลงทุนไปกับพรีเซนเตอร์คนนั้น ประสบความสำเร็จมากน้อยแค่ไหน”
ซึ่งนวีนก็บอกว่า PageLink น่าจะเป็นเครื่องมือที่ดีสำหรับแบรนด์ในการใช้ข้อมูลมหาศาลในโซเชียลมีเดียเพื่อเอาไปวางแผนการตลาด เลือกศิลปินให้เข้ากับแบรนด์ วางแผนการเลือกสื่อประชาสัมพันธ์ หรือหาช่องทางในการขยายกลุ่มลูกค้า หรืออาจต่อยอดไปมองภายใหญ่ในเชิงสังคมก็ได้ เราก็จะสามารถเห็นทิศทางของกระแสสังคมว่าตอนนั้นสนใจเรื่องอะไรกัน
“ผมรู้สึกว่าการตัดสินใจ ส่วนใหญ่ถ้าทำด้วยข้อมูลมันให้ผลลัพธ์ที่ดีกว่าอยู่แล้ว แต่ก็ต้องระวังในเรื่องความถูกต้องของข้อมูลด้วย ส่วนความสนุกในการทำงานกับข้อมูล มันก็เหมือนกับการที่เราหาสมบัติ แต่บังเอิญไปเจอ insight อย่างอื่นที่ไม่ได้ตั้งใจหา นั่นแหละครับ ความตื่นเต้นมันอยู่ตรงนั้น”
ลองเข้าไปดูผลงาน PageLink ได้ที่ https://pnaveen.com/datacafe/pageLink.html
LSTM

“เวลาไปขึ้นเงินไม่ต้องมีพิธีแสดงความยินดีอะไรทั้งนั้น ไม่ต้องทำข่าว จ่ายเช็คเซ็นชื่อแล้วเดินออกมาเลยได้ไหม?” นี่เป็นหนึ่งข้อความในกระทู้พันทิป พอรู้ไหมว่าเจ้าของกระทู้กำลังพูดถึงเรื่องอะไร? ใช่แล้ว! หัวข้อกระทู้คือ “ถูกหวยรางวัลที่ 1 ไม่ให้ใครรู้เลยได้ไหม?”
ขยับสายตาลงมาอีกนิดจะเจอกับแท็ก ‘การเงิน’ ‘ภาษีเงินได้’ ‘สลากกินแบ่งรัฐบาล’ ซึ่งทั้งในชื่อและข้อความในกระทู้ไม่มีข้อความเหล่านี้ปรากฏอยู่เลย
‘พิชญุตม์ อุปพันธ์’ เจ้าของโปรเจ็กต์ LSTM ตั้งข้อสังเกตว่า “จริงๆ แท็กเหล่านี้แหละครับ ที่ช่วยให้การค้นหากระทู้ง่ายขึ้น รวมถึงทำให้คนถามได้คำตอบที่รวดเร็วขึ้นด้วย ผมเลยคิดว่าถ้าเอาข้อมูลตรงนี้มาสอนให้คอมพิวเตอร์เรียนรู้ด้วยวิธี Machine Learning ต่อไปมันก็จะติดแท็กให้เราโดยอัตโนมัติได้เลย”
พิชญุตม์ได้หยิบเอาข้อความประมาณ 300,000 โพสต์ในพันทิป ซึ่งมีการจัดหมวดหมู่ด้วยแท็กทั้งหมด 19,547 แท็ก มาสอนระบบแล้วก็พบว่ามีความแม่นยำพอๆ กับที่มนุษย์อย่างเราเลือกแท็กเองเลย เขายังมองอีกว่าสามารถนำระบบนี้ไปใช้กับเว็บไซต์หรือโซเชียลอื่นๆ ก็ยังได้
เพราะข้อมูลทุกวันนี้มีจำนวนเยอะมาก เราควรให้คอมพิวเตอร์ช่วยจัดการและจำแนกข้อมูลเหล่านั้น เพื่อเอาไปสร้างโอกาสหรือประโยชน์ทางธุรกิจหรือสังคมได้