
วันนี้ปฏิเสธไม่ได้ว่าปัญญาประดิษฐ์หรือเอไอ (AI – artificial intelligence) กำลังเป็นดาวเด่นในโลกนวัตกรรมและเทคโนโลยี กำลังเข้ามามีบทบาทมากขึ้นเรื่อยๆ ในชีวิตของเรา และหากเปรียบเอไอเป็นระบบสุริยะ อัลกอริทึมแบบ ‘ระบบเรียนรู้เชิงลึก’ (deep learning) วันนี้ก็เปรียบเสมือนดวงอาทิตย์ที่ส่องสว่างสุกสกาว หลังจากที่กบดานมานาน
วันนี้เราได้ยินข่าวแทบไม่เว้นแต่ละวันว่าเอไอเก่งขึ้นขนาดไหน มันไม่เพียงแต่สามารถแยกแยะใบหน้าคน (เวลาที่เรากดดูฟังก์ชั่น Photo Review ในเฟซบุ๊ก แล้วทึ่งว่าเฟซบุ๊ก ‘รู้จัก’ แยกแยะหน้าเราจากมุมต่างๆ ได้อย่างไร นั่นคือผลงานของระบบเรียนรู้เชิงลึก ซึ่งมันก็เรียนรู้จากการติดแท็กหน้าเพื่อนของเรานั่นแหละ) และแยกแยะวัตถุต่างๆ (เวลาที่เราเข้าเว็บแล้วถูกขอให้คลิกรูปทุกใบในตารางที่มีภูเขา รถยนต์ หรือวัตถุอื่นๆ เพื่อยืนยันว่าเราเป็นคน นั่นคือเรากำลังส่งข้อมูลที่ช่วยให้เอไอแยกแยะได้เก่งขึ้น) แต่ยังสามารถวินิจฉัยโรคมะเร็งผิวหนังและออทิสติกได้อย่างเที่ยงตรงไม่แพ้หมอ ปลอมงานศิลปะได้อย่างเหมือนจริงจนแยกไม่ออก และขับรถยนต์ด้วยตัวเองเก่งขึ้นเรื่อยๆ (ความท้าทายประการหนึ่งที่กูเกิลรายงาน ก็คือหลังจากที่ผ่านไปหลายล้านกิโลเมตร รถยนต์ขับตัวเองยังมีปัญหากับการเลี้ยวเข้าเลนทางด่วน เพราะมันยังกลัวเสี่ยงมากเกินไป)
เอไอที่กล่าวไปข้างต้นล้วนแต่ใช้อัลกอริทึมแบบระบบเรียนรู้เชิงลึก ซึ่งเป็นชื่อใหม่ (หรืออาจจะเรียกว่า ผ่านการ ‘รีแบรนด์’) ของ ‘โครงข่ายใยประสาทเสมือน’ (artificial neural networks) โครงการแนวนี้ถูกออกแบบมาให้เลียนแบบโครงสร้างและวิธีทำงานของระบบประสาทในสมองมนุษย์ โดยให้ ‘เซลล์ประสาท’ เชื่อมโยงกันเป็น ‘ระบบประสาท’ ใช้วิธีประมวลผลแบบขนาน (parallel processing) ทำให้มันสามารถ ‘รับรู้’ และ ‘เรียนรู้’ ได้อย่างต่อเนื่อง และเมื่อมีข้อมูลดิบมากขึ้น ก็จะสามารถประเมินชุดข้อมูลจนตัดสินใจได้ใกล้เคียงกับมนุษย์
คำว่าโครงข่ายใยประสาทเสมือนหรือ neural networks ถูกแทนที่ในการรับรู้ของผู้คนด้วยคำว่าระบบเรียนรู้เชิงลึกหรือ deep learning ราวปี ค.ศ. 2006 นี้เอง เมื่อ เจฟฟรีย์ ฮินตัน (Geoffrey Hinton) นักวิทยาศาสตร์การรับรู้และนักวิทยาศาสตร์คอมพิวเตอร์ เสนอความคิดว่าเราสามารถ ‘ฝึก’ โครงข่ายเสมือนได้ด้วยการใช้แบบจำลองสองชั้นที่ไม่ต้องมีการควบคุม (unsupervised) แช่แข็งตัวแปรต่างๆ เอาไว้ แปะชั้นใหม่เข้าไปข้างบนและฝึกเฉพาะตัวแปรสำหรับชั้นใหม่ ทำแบบนี้ไปเรื่อยๆ จนกระทั่งเครือข่ายมีความลึกมากพอ (มีอัตราผิดพลาดน้อยมากแล้ว) จากนั้นก็ใช้ผลลัพธ์จากกระบวนการนี้ไปจุดติดตัวแปรของโครงข่ายเสมือนต่อไป วิธีนี้ทำให้นักวิจัยสามารถฝึกเครือข่ายได้ลึกกว่าที่เคยเป็นมา ส่งผลให้คำว่า ‘neural networks’ ถูกรีแบรนด์เป็น ‘deep learning’ หรือระบบเรียนรู้เชิงลึกโดยปริยาย ในเมื่อวันนี้โครงข่ายใยประสาทเสมือนล้วนแต่ใช้วิธีนี้
สาเหตุที่ระบบเรียนรู้เชิงลึกกำลังเป็นแฟชั่นและเป้าหมายเงินลงทุนหลายพันล้านเหรียญสหรัฐฯ จากบริษัทไอทีชั้นนำทุกแห่งในโลกในวันนี้ ก็คือส่วนผสมที่ลงตัวเหมาะเจาะระหว่างแนวคิดอัลกอริทึมเรียนรู้เชิงลึก ความก้าวหน้าด้านวิศวกรรมซอฟต์แวร์ การออกแบบวงจรคอมพิวเตอร์ ข้อมูลมหาศาลผ่านเครือข่ายอินเทอร์เน็ต การคิดค้นเทคนิคเพิ่มประสิทธิภาพและลดอัตราผิดพลาด (optimization) ตลอดจนหยาดเหงื่อแรงงานรวมกันนับแสนนับล้านชั่วโมงของนักวิจัยหลากแขนงผู้อุทิศทั้งชีวิต ถึงแม้ว่าแนวคิดหลักเบื้องหลังระบบเรียนรู้เชิงลึกจะมีมานานหลายทศวรรษแล้วก็ตาม นักวิจัยก็เพิ่งมีชุดข้อมูลมหาศาล และคอมพิวเตอร์ก็เพิ่งมีพลังประมวลผลมากพอและเร็วพอ (โดยเฉพาะพลังประมวลผลแบบขนานของ GPU หรือหน่วยประมวลผลด้านกราฟิก) เมื่อไม่นานมานี้เอง—มากพอที่จะทำให้ระบบเรียนรู้เชิงลึกเผยพลังที่แท้จริงของมันออกมา
พูดง่ายๆ ก็คือ ความก้าวหน้าทางวิศวกรรมศาสตร์และการมีข้อมูลมหาศาลหรือ big data เปรียบเสมือนหัวจักรและเชื้อเพลิงที่จุดติดแนวคิดเรื่องโครงข่ายใยประสาทเสมือน ขับเคลื่อนให้เอไอวันนี้เรียนรู้ได้เร็วกว่าในอดีตหลายเท่า และนับวันมันก็จะยิ่งเก่งขึ้นอย่างไม่หยุดยั้ง
จึงเป็นเรื่องของเวลาเท่านั้นเอง ที่เราจะได้เห็นเกมที่ถ่ายทอดความมหัศจรรย์ของระบบเรียนรู้เชิงลึกในรูปแบบที่เข้าถึงง่ายและเข้าใจไม่ยากสำหรับคนทั่วไป ในเมื่อเราก็มีเกมที่สอนเรื่องการเขียนโปรแกรมทยอยออกมามากมายหลายร้อยเกมแล้ว ซึ่งมันก็สนุกและเข้าถึงง่ายมากขึ้นเรื่อยๆ (อ่านเรื่องเกม Exapunks ได้ที่นี่)
เกมที่ต้องจารึกไว้ว่าเป็นเกมแรกในประวัติศาสตร์ที่ถ่ายทอดการทำงานของระบบเรียนรู้เชิงลึก สอดแทรกเกร็ดความรู้และประวัติศาสตร์ของวงการ แถมยังทำออกมาได้สนุกสนานเลยทีเดียว คือ while True: learn() เกมแก้ปริศนาตรรกะ (logic puzzles) จากสตูดิโออินดี้ชื่อ Luden.io
ทีมนักพัฒนา while True: learn() รู้ดีว่าเกมที่สอนปัญญาประดิษฐ์หรือการเขียนโปรแกรมโดยทั่วไปนั้นน่าหวาดหวั่นครั่นคร้ามเกรงขามสำหรับคนนอกวงการ ด้วยความที่มันเต็มไปด้วยนามธรรม ตัวเลข ตรรกะ และสมการน่าเวียนหัว ด้วยเหตุนั้นจึงตั้งใจออกแบบเกมนี้ให้ดูน่ารักและเข้าถึงง่ายในทุกมิติ ตั้งแต่กราฟิกการ์ตูนสีสันสดใส อินเทอร์เฟซ (interface) ใช้ง่าย ไปจนถึงเส้นเรื่องหลุดโลกสุดเพี้ยนแต่ก็เรียกรอยยิ้มและทำให้เราอยากติดตามไปจนจบ—เราเล่นเป็นนักเขียนโปรแกรมฟรีแลนซ์ จู่ๆ วันหนึ่งเจอแมวสุดที่รักกำลังพิมพ์แก้บั๊ก (bug) ของโปรแกรมเราอยู่! ด้วยความตื่นเต้นแต่ไม่ตื่นตระหนก เรารีบเข้าเน็ตไปหาความรู้ว่าแมวฉลาดขนาดนี้ได้อย่างไร (แล้วเราจะฉลาดเท่ามันได้อย่างไร) เริ่มจากการเขียนโปรแกรมเพื่อพูดภาษาแมว และเรียนรู้อารมณ์ความรู้สึกของแมว
ระหว่างทาง เราจะได้ทำภารกิจ (แก้ปริศนาตรรกะหรือ logic puzzles) ทางเลือกมากมายที่ช่วยทำให้เราเข้าใจแนวคิดหลักๆ ที่ได้เรียนรู้ระหว่างเกมมากขึ้น
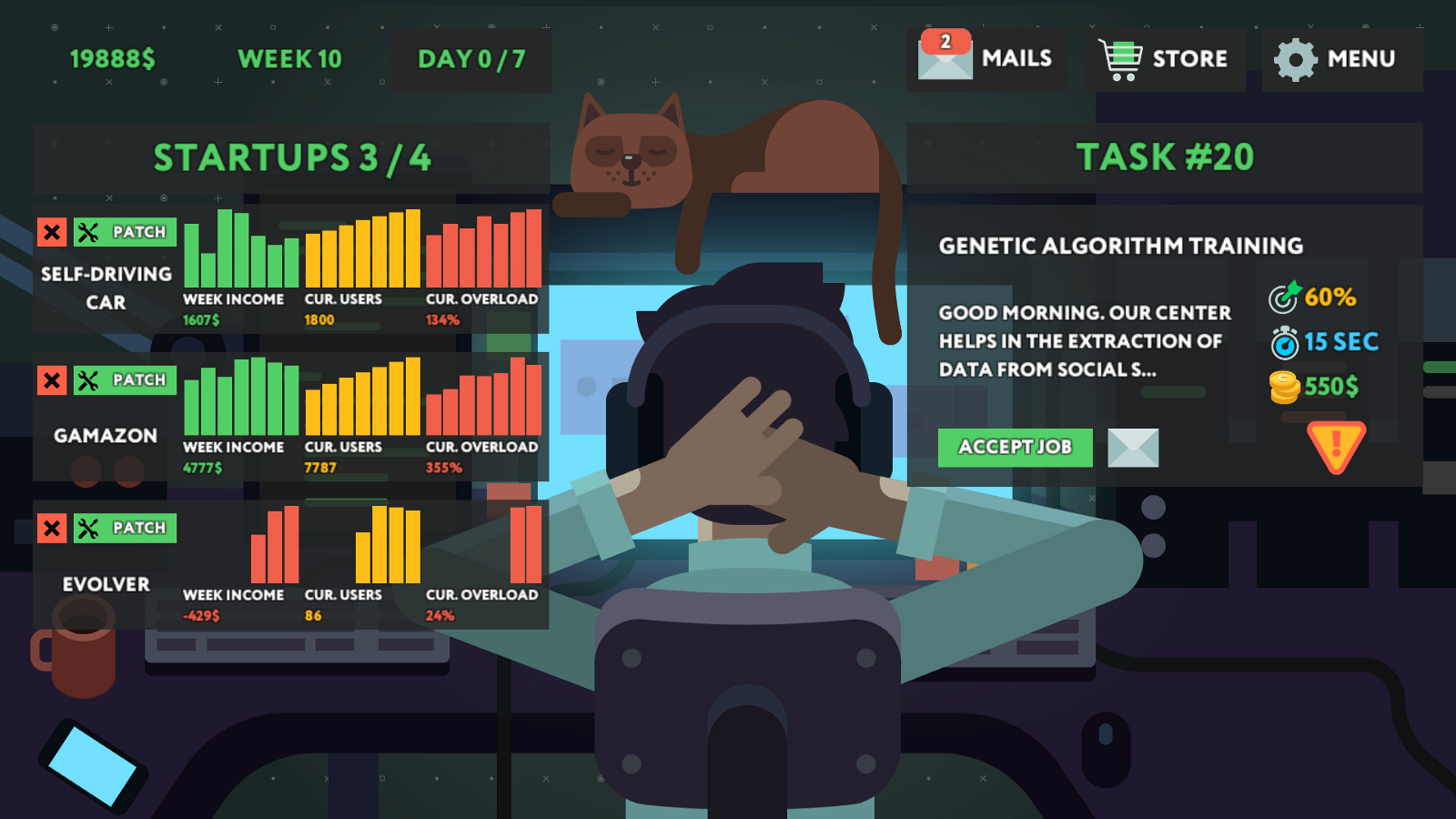
รวมถึงแก้ปริศนาทางเลือกอีกหลายชิ้นที่ไม่เกี่ยวกับเส้นเรื่องหลัก แต่ทำในฐานะงานของกิจการเกิดใหม่ (startup) เพื่อสร้างรายได้และกำไรในเกมให้กับเรา ยิ่งเราหาวิธีปรับปรุงอัลกอริทึมเรียนรู้เชิงลึกสำหรับโจทย์แต่ละข้อให้มีข้อผิดพลาด (error rate) น้อยลง และทำงานตามเป้าได้เร็วขึ้นเท่าไร เราก็จะยิ่งประหยัดค่าเซิร์ฟเวอร์ในเกมและได้เงินมากขึ้นเป็นเงาตามตัว
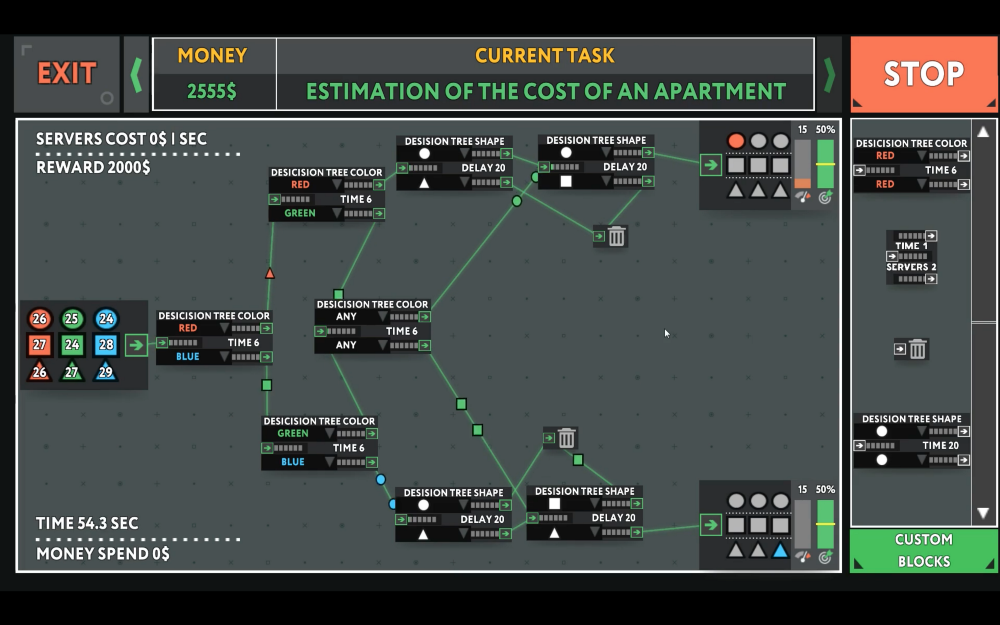
การแก้ปริศนาตรรกะต่างๆ ในเกมนี้ดูเผินๆ ไม่ต่างจากเกมเขียนโปรแกรมเกมอื่นมากนัก เราจะใช้ ‘กล่องตรรกะ’ หรือ logic blocks ในเกมซึ่งถูกเขียนโปรแกรมบางอย่างขึ้นมาล่วงหน้าแล้ว (เช่น ‘วัตถุนี้เป็นสี่เหลี่ยม’) หน้าที่ของเราคือการหาวิธีเชื่อมกล่องเหล่านี้เข้าด้วยกันเพื่อบรรลุวัตถุประสงค์ในแต่ละฉาก (เช่น ‘คัดเฉพาะรูปสี่เหลี่ยมไปเข้าถังสี่เหลี่ยมอย่างน้อย 8 อัน รูปทรงอื่นให้ทิ้งไป อัตราผิดพลาดต้องเท่ากับศูนย์’)
เราไม่ต้องมีประสบการณ์ใดๆ ในการเขียนโค้ดคอมพิวเตอร์มาก่อนก็เล่นเกมนี้ได้ แต่ระหว่างทางเราจะเข้าใจวิธีคิดของโปรแกรมเมอร์ในการแก้ปัญหา และเริ่มเข้าใจประวัติศาสตร์และวิธีทำงานของระบบเรียนรู้เชิงลึก ส่วนคนที่เขียนโค้ดเป็นอาชีพอยู่แล้วก็จะได้เรียนรู้เรื่องระบบเรียนรู้เชิงลึกหรือ deep learning และพัฒนาการของมัน

while True: learn() ถูกออกแบบมาให้เข้าถึงง่าย ทั้งเกมแบ่งออกเป็นสองส่วนใหญ่ ส่วนแรกคือโต๊ะทำงานของเราในเกม จากจอนี้เราสามารถเช็คอีเมล ดูต้นไม้ (tree) เป้าหมายว่าจะต้องทำอะไรต่อ ติดตามและปรับปรุงการทำงานของระบบเรียนรู้เชิงลึกที่เราฝึกมาทำเงินในฐานะกิจการเกิดใหม่ และใช้เงินที่ได้มาในการอัพเกรดฮาร์ดแวร์ ซื้อกล่องตรรกะ (logic block) ที่ซับซ้อนมากขึ้น ซื้อชุดแต่งตัวมันส์ๆ ให้กับแมวอัจฉริยะของเรา และซื้อของตกแต่งบ้าน ส่วนที่สองในเกมคือจอที่ใช้สำหรับแก้โจทย์ หน้าตาเหมือนจอเขียนโปรแกรมด้วยภาพ (visual programming) จุดเริ่มต้นอยู่ด้านซ้าย เป้าหมายอยู่ทางขวา ไม่ต้องพิมพ์อะไรเข้าไปในเกม เพียงแต่ใช้เมาส์คลิกเลือกกล่องที่เหมาะสมและลากเส้นเชื่อม จุดที่เจ๋งและสะดวกมากก็คือ วิธีแก้โจทย์ที่เราทำสำเร็จแล้วในฉากก่อนๆ จะถูกเซฟเก็บไว้ กลายเป็น ‘กล่อง’ (block) (เช่น ‘แยกเฉพาะสีแดง’) ให้เราหยิบมาใช้เป็นโหนด (node) ในการแก้โจทย์ในฉากต่อๆ ไปได้ ซึ่งเราก็สามารถโค้ดกล่องใหม่ๆ ได้ทุกเมื่อด้วยฟังก์ชั่น custom block
ปริศนาหรือโจทย์ทุกชิ้นในเกมนี้จะให้รางวัลเราเมื่อทำสำเร็จ แบ่งเป็นระดับ เหรียญทอง เหรียญเงิน และเหรียญทองแดง ดูจากความเร็วและระดับความเที่ยงตรง (อัตราความผิดพลาดต่ำ) ที่เราทำได้ ชนิดของเหรียญที่เราได้มากที่สุดในเกมจะเป็นตัวกำหนดว่าเราจะได้เห็นฉากจบแบบไหน สร้างแรงจูงใจให้เราหาทางปรับปรุงตัวเอง (คือถ้าเราไม่มีแรงจูงใจแบบนักสมบูรณ์แบบนิยมที่ทนเห็นเหรียญเงินหรือทองแดงไม่ได้) ฉากแรกๆ จะค่อนข้างง่าย แต่ความยากจะไต่ระดับขึ้นอย่างรวดเร็ว ไม่ต่างจากเกมแก้พัสเซิลทั่วไป เป็นไปได้ที่ทางออกของเราจะบรรลุเป้าหมายแล้ว แต่ยังใช้เวลานานเกินกว่ากำหนด ทำให้ต้องหาทางปรับปรุงประสิทธิภาพ
while True: learn() ไม่เพียงแต่ถ่ายทอดวิธีทำงานของระบบเรียนรู้เชิงลึก (deep learning) ผ่านการออกแบบปริศนาต่างๆ เท่านั้น แต่ยังถ่ายทอดประวัติศาสตร์ของวงการ และแนะนำแหล่งข้อมูลในโลกจริงให้เราไปเรียนรู้เพิ่มเติมด้วยตัวเองอย่างชาญฉลาด
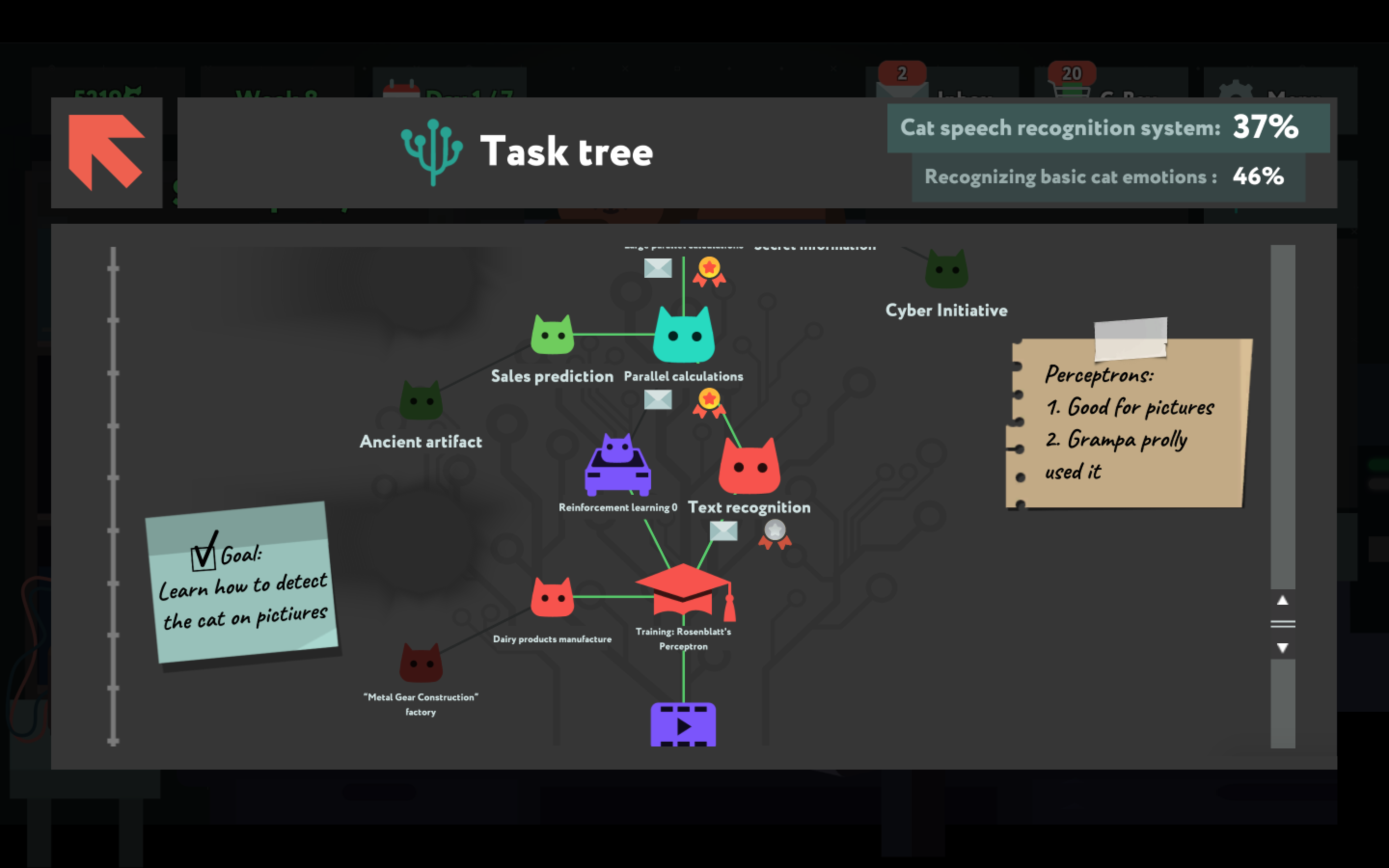
ด้วยการออกแบบจอเลือกฉากให้แสดงเป็น ‘เส้นเวลา’ (timeline) ที่เราค่อยๆ ไต่เต้า เส้นเวลาแสดงแนวคิดสำคัญๆ ของวงการเรียนรู้เชิงลึกและโครงข่ายใยประสาทเสมือนตามทศวรรษที่มันถูกคิดค้นขึ้นจริงๆ วางแนวคิดใหม่ๆ ที่เราจะได้เรียนรู้ในฉากนั้นไว้บนเส้นเวลา พร้อมแสดงแหล่งข้อมูลทั้งคลิปวีดีโอยูทูบและลิงก์ข้อมูลอื่น เราจะได้ไปดูได้ว่าเทคนิคที่เราใช้ในฉากนั้น เขาใช้กันในโลกจริงอย่างไร
ยกตัวอย่างเช่น ฉากแรกๆ ในเกมนี้แนะนำแนวคิดเบื้องหลัง Perceptron อัลกอริทึมแยกแยะแบบเส้นตรง (linear) คิดค้นในปี ค.ศ. 1957 โดย แฟรงค์ โรเซนบลาท (Frank Rosenblatt) ผู้บุกเบิกโครงข่ายใยประสาทเสมือนสมัยใหม่ อัลกอริทึมนี้ของเขาสามารถแยกแยะตัวเลขและตัวอักษรได้ แม้จะมีข้อจำกัดมากเมื่อเทียบกับอัลกอริทึมในยุคต่อมา หลังจากที่แก้ปริศนาในฉากนี้สำเร็จ เราก็จะเข้าใจวิธีทำงานของ Perceptron มากขึ้นและหาข้อมูลเพิ่มเติมได้
จุดที่ผู้เขียนรู้สึกว่าเกมนี้อ่อนไปหน่อยคือกลไกกิจการเกิดใหม่ เราสามารถเลือกได้ว่าสนใจจะออกแบบอัลกอริทึมมาช่วยกิจการไหนบ้างในเกม สูงสุดช่วยได้คราวละ 4 กิจการ โจทย์เหล่านี้ไม่แตกต่างมากนักกับปริศนาที่เราต้องแก้เป็นภารกิจหลัก จุดที่ต่างคือมันทำให้เรามีเงินใช้ทุกสัปดาห์ในเกม ยิ่งปรับปรุงประสิทธิภาพของอัลกอริทึมได้ดี เรายิ่งได้กำไรมาก ความสนุกอยู่ที่การหาทางปรับปรุงประสิทธิภาพ โดยเฉพาะเมื่อเราสามารถซื้อกล่องตรรกะที่ดีกว่าเดิม (ยิ่งแก้ปริศนาหลัก ขยับเส้นเรื่องไปข้างหน้า จะยิ่งปลดล็อกกล่องตรรกะใหม่ๆ ได้) แล้วนำมันมาใช้แทนกล่องหรือโหนดเดิม ปัญหาก็คือบางครั้งไม่ชัดเจนว่าผู้ก่อตั้งบริษัทเกิดใหม่ต้องการอะไรกันแน่ ทำให้เราไม่สามารถ ‘แปล’ ความต้องการของเขาในภาษามนุษย์ (เช่น ‘ลดต้นทุนบริษัทลง 20%’) มาเป็นโจทย์ที่จะฝึกเอไอของเราได้ทันที
กราฟิกน่ารัก ความตลกขบขันของเนื้อหา (อีเมลในเกมหลายฉบับเขียนโดย ‘เกรียนคีย์บอร์ด’ ที่เกรียนสมจริงมาก) แถมจิกกัดแมว วงการสตาร์ทอัพ และเอไอแบบกำลังดี ถูกนำมาผสมเข้ากับเส้นเรื่องหลุดโลกแต่น่าติดตาม ความสมจริงของแนวคิดแต่ละชิ้นของวงการ deep learning ที่ทำให้เราเข้าใจและอัศจรรย์ใจมากขึ้นในพัฒนาการของดาวเด่นเอไอ จาก Perceptron มาถึงรถยนต์ขับตัวเองและเทคโนโลยีล้ำยุคอื่นๆ รวมถึงการสอดแทรกเกร็ดความรู้และประวัติศาสตร์ที่แนบเนียนและสนุกสนานไม่น่าเบื่อไปตลอดทาง
ทั้งหมดนี้ทำให้ while True: learn() ควรค่าแก่การเล่น และสอนลูกสอนหลานให้เล่น เพื่อฝึกทักษะการเรียนรู้ การใช้ตรรกะ และทำความเข้าใจกับ ‘โลกใหม่’ ของปัญญาประดิษฐ์—โลกที่กำลังคืบคลานเข้ามาใกล้ตัวเรามากขึ้นทุกขณะ
เราจะได้เข้าใจโลกใหม่นี้มากขึ้น ตื่นเต้นกับความก้าวหน้าทางเทคโนโลยีอย่างมีเหตุมีผล และกังวลในประเด็นที่ควรกังวล มิใช่พากันแตกตื่นตูมตามด้วยความไม่รู้ของเราเอง

สฤณี อาชวานันทกุล









